Q2RL: Two-Phase Framework
Q-Estimation
We estimate the Q-function of the pretrained BC policy by assuming its action distribution approximates a Boltzmann distribution. Using only the BC policy's action log-probabilities and entropy (no training data required) we derive:
The value function $V_{BC}$ is estimated via Monte Carlo returns from a small number of initial rollouts.
Q-Gating
During online RL, Q-Gating maintains two Q-functions: a frozen $\hat{Q}_{BC}$ (preserving BC performance) and a trainable $Q_{RL}$ (enabling improvement). At each step, the action with the higher Q-value is executed:
This mechanism prevents catastrophic forgetting of good BC actions while allowing the RL policy to explore and improve in states where BC is suboptimal. An auxiliary BC loss further stabilizes training for safe on-robot deployment.
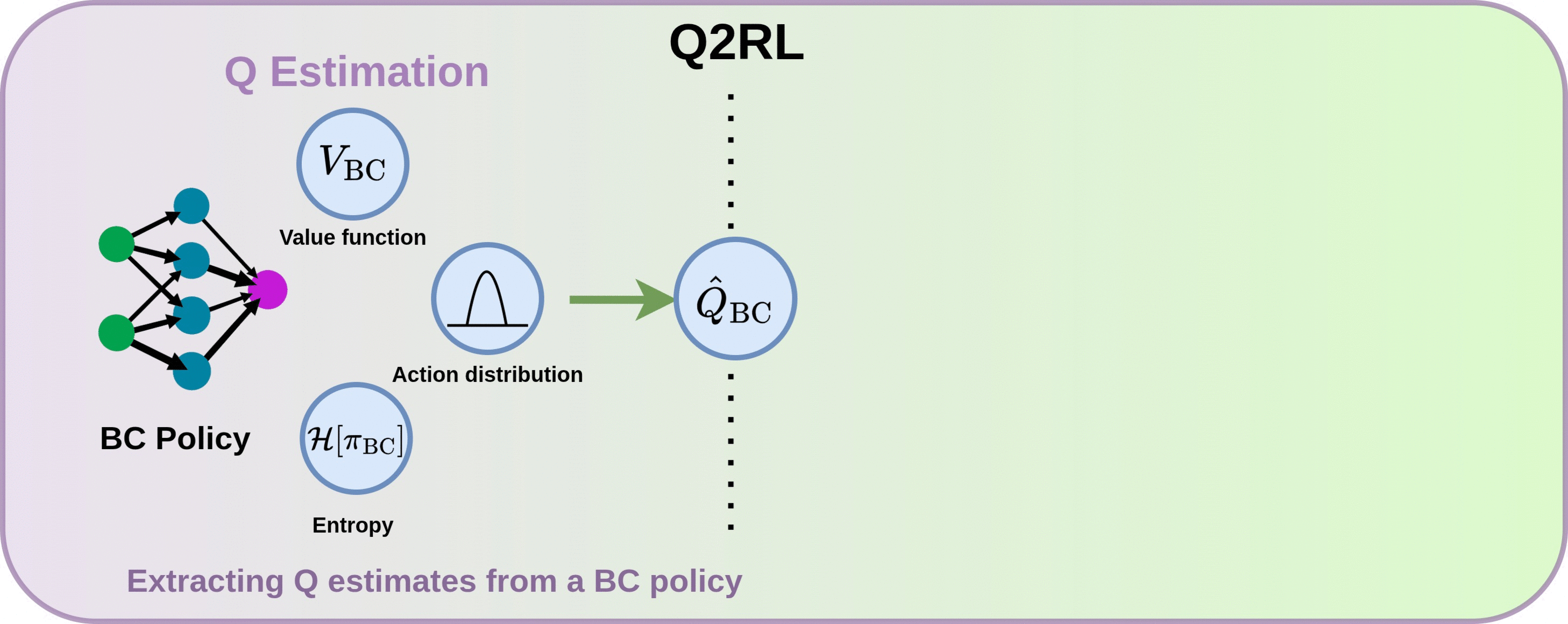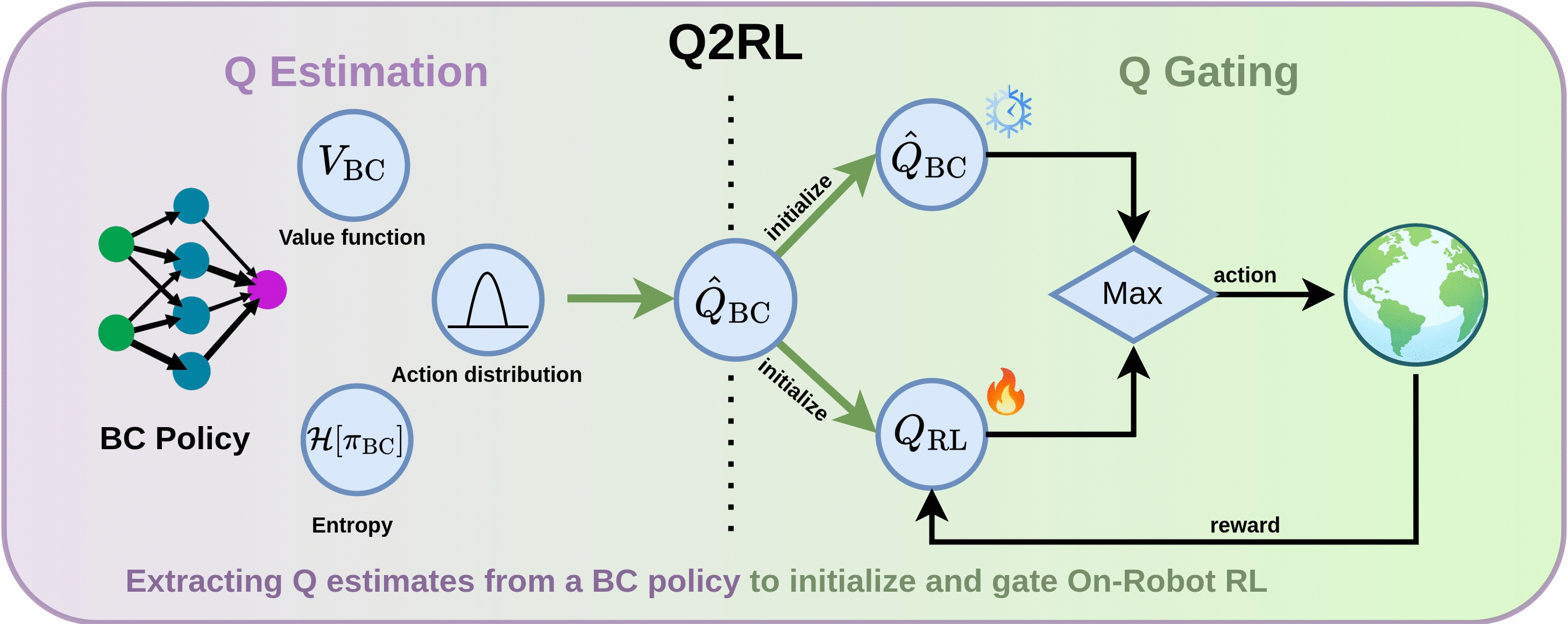
Q2RL consists of Q-Estimation and Q-Gating. Q-Estimation extracts a Q function from a BC Policy using its value function, action log-probabilities, and entropy. During RL policy training, Q-Gating selects and executes the BC or RL action with highest respective Q-value, updating the RL policy on the collected interactions.
BC for simple motions
Q2RL relies on the BC policy for smooth, well-practiced motions such as reaching and initial alignment, where BC is confident and performant.
RL for contact-rich segments
RL takes over for high-precision, contact-rich segments like insertion, where the BC policy struggles and precise force-aware control is needed.
RL for error recovery
When BC gets stuck or mis-grasps, RL handles recovery behaviors such as re-grasping and re-alignment, overcoming common BC failure modes.